开源不易,还请您点个 Star 多谢!🎉
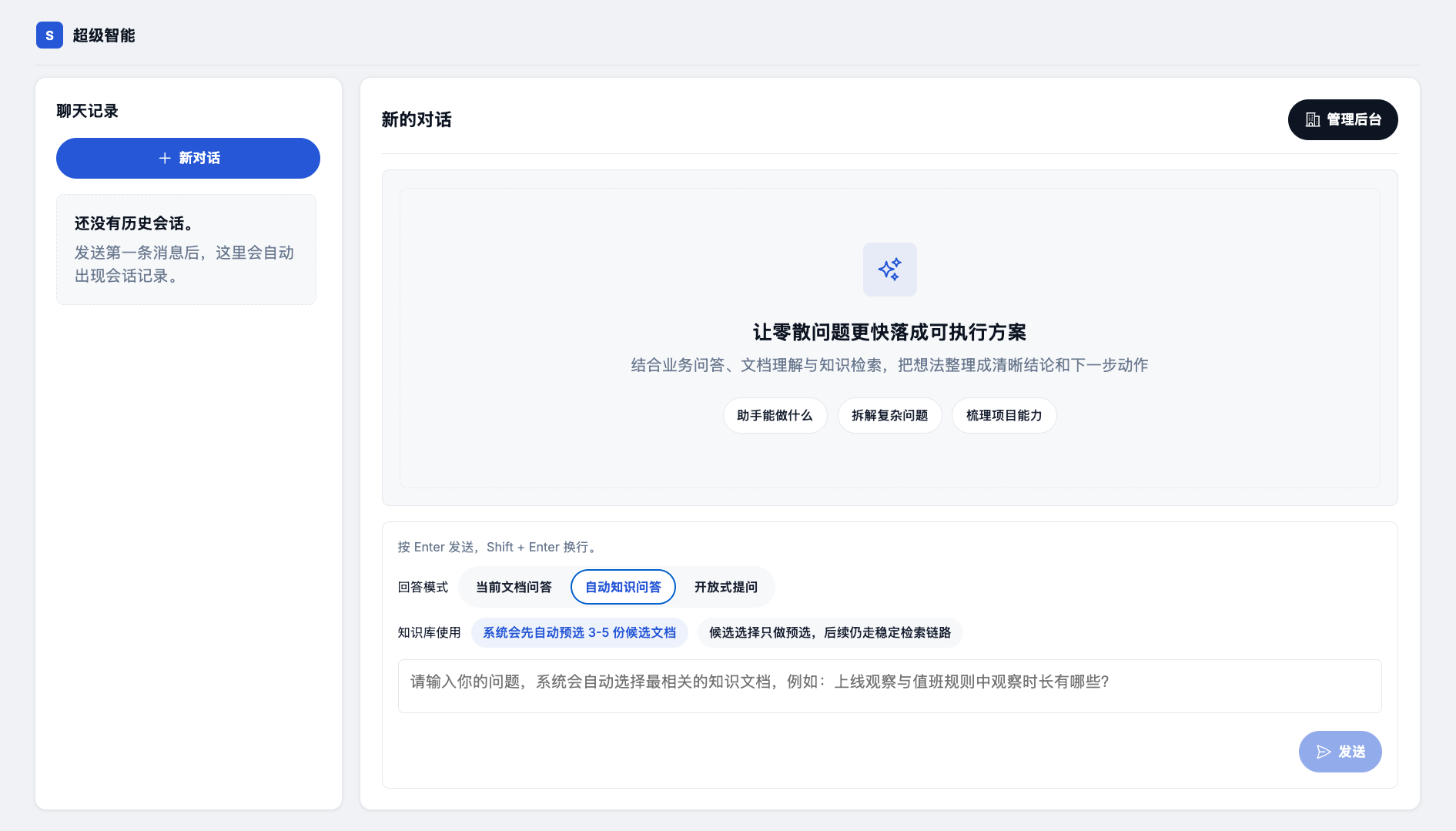
Super Agent 是一个 企业级 的 AI 智能体对话平台,覆盖了智能对话、文档知识问答、联网搜索、RAG 详细检索、MCP 工具协议、Skills 能力扩展、文档全生命周期管理等完整能力。
项目从对话入口开始,到意图分析、检索决策、多路知识召回、证据驱动生成,再到会话记忆管理、MCP 外部工具集成和文档治理,每一个环节都不是简单调个接口就完事的,而是经过深度设计和反复打磨的工程化实现。
现在的 Java 面试,光靠八股文和 CRUD 项目已经越来越难了。微服务、高并发这些之前算是亮点的东西,现在也慢慢成了标配。面试官开始问:RAG 是什么?Agent 怎么实现的?会话记忆怎么设计?向量检索用的什么方案?你做过文档问答吗? 这些问题已经从加分项变成了必答题。
但问题是,大多数人学 AI 的方式是跟着教程调一下 API,往向量库里塞点数据,让模型输出一段话——结束了。这顶多算跑通了一个 Demo,面试官一追问就露馅。真正的 AI 应用和调 API 之间,差的不是代码量,是对每个环节的深入理解和工程化设计。
而 Super Agent 就是为了解决这个问题:它覆盖了 Agent 智能体、RAG 检索增强生成、MCP 工具协议、Skills 能力扩展、会话记忆管理、文档生命周期治理 这些 AI 应用层的核心技术,每一块都有完整的设计和代码实现,复杂度对标真实企业级系统。不管是学生还是工作了几年的同学,学完之后面试中都能真正聊得起来,而且聊得有深度。
很多人觉得自己"会 RAG 了"、"懂 Agent 了",但面试一深入就露馅。在正式介绍项目之前,先把几个常见误区理清楚。
很多教程的套路是:调一下 Embedding 接口,往向量数据库里塞点数据,再用大模型生成答案——完事了。这顶多算跑通了一个 Demo。
真正的 RAG 系统要考虑的问题多得多:文档怎么切分效果最好?检索召回率不够怎么办?多路召回怎么融合排序?幻觉怎么控制?这些才是面试官会追问的点。跑通 Demo 和做出能上线的系统之间,差的不是代码量,是对每个环节的深入理解。
Retrieval-Augmented Generation 这个名字容易让人觉得就是检索加生成。但实际工程中,一个能用的 RAG 系统至少涉及这些环节:
- 数据处理:PDF、Word、PPT,格式五花八门,光是解析成干净文本就是一堆脏活
- 分块策略:切太大检索不精准,切太小上下文丢失。不同文档可能需要不同策略
- 问题改写:用户问"那它怎么配置?",不补上下文系统根本不知道在问啥
- 检索策略:纯向量检索对精确匹配很弱,用户问一个订单号,向量检索可能完全找不到。混合检索怎么融合、要不要重排序,都是取舍
- 会话记忆:20 轮对话全塞给模型?Token 成本扛不住。只带最近几轮?可能丢关键上下文
每一环都有坑,每一环都值得深挖。面试的时候能把这些讲清楚,比背概念有用得多。
RAG 项目的核心竞争力不在于你用了多强的模型,而在于工程化能力。同样的模型,检索策略不同、Prompt 设计不同、分块粒度不同,最终效果可以天差地别。
举个例子:用户问 "打印机墨盒怎么换",文档里写的是 "墨盒更换步骤"。关键词搜索直接匹配不上,但向量检索能理解它们是一回事。这背后是 Embedding 模型的选型、向量数据库的调优、检索结果的重排序——每一步都是工程决策,不是换个更贵的模型就能解决的。
Spring AI / LangChain4j 是好工具,但直接拿来用是远远不够!
执行器路由、前置编排器五步决策链、双通道检索融合、Parent-Child 块聚合、证据预算控制与无证据短路、组合式切块引擎、摘要压缩记忆、集群级租约互斥、全链路观测追踪。这些构成项目核心竞争力的能力,这些框架并不具备的能力,在此项目中全都有实现。
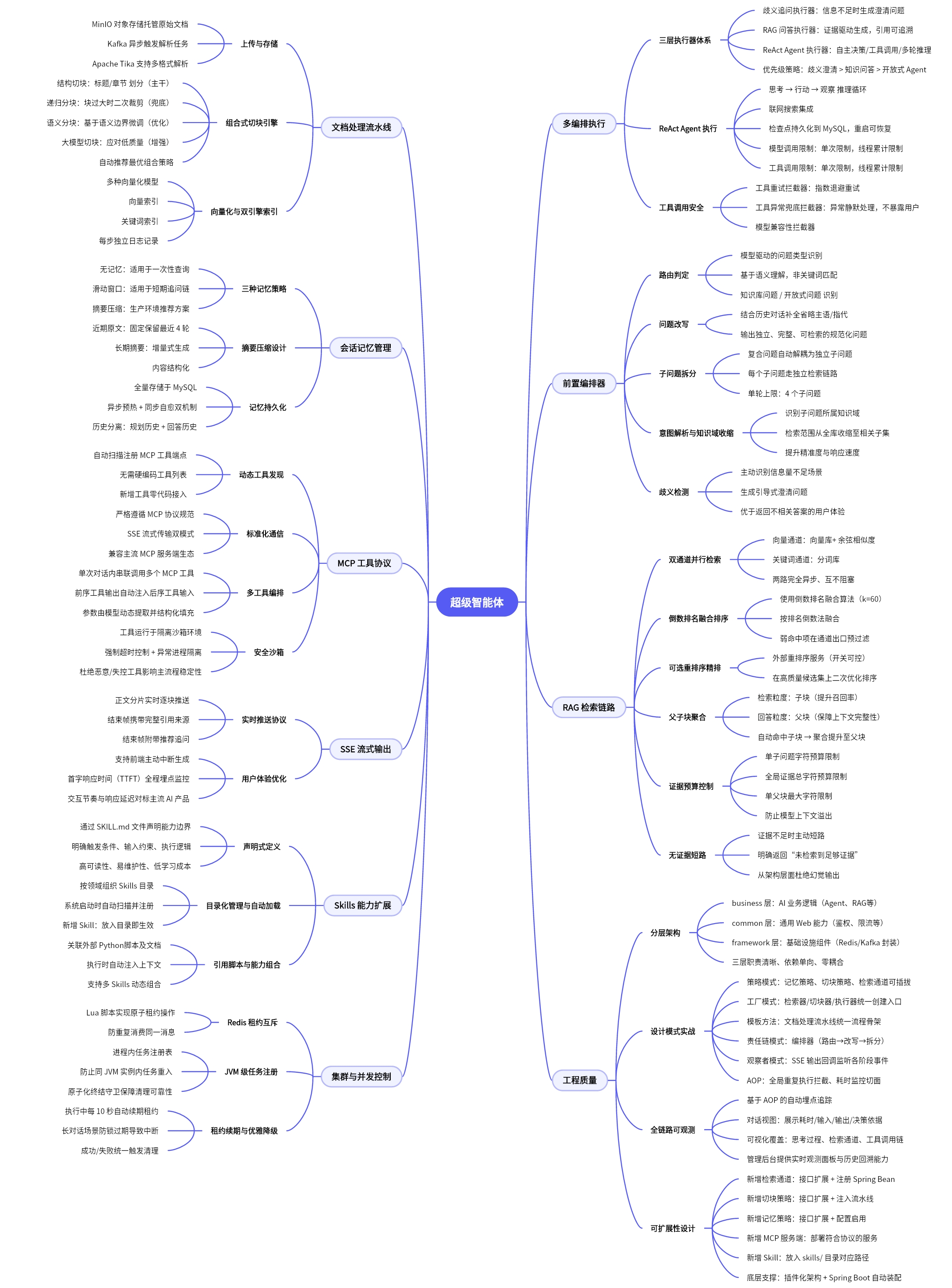
先直接列出来,小伙伴心里有数:
-
ReAct Agent 智能体的完整实现:不只是能聊天,而是支持联网搜索、工具调用、多步推理、Checkpoint 持久化,真正能自主决策和行动的 Agent
-
三层执行器体系:系统不是把所有问题都交给 Agent,而是先做确定性编排,再按场景选最合适的回答引擎(歧义追问 / 知识问答 / 开放式 Agent),这套分层调度机制是整个系统的核心竞争力
-
Neo4j 图数据库驱动的文档结构图谱:每份文档在索引构建时,会同步在 Neo4j 中生成 Document → Section → Item 的层级图结构,支持章节编号定位、邻接遍历、子节点展开等图查询,让检索不再只靠向量匹配,还能沿着文档结构精准导航
-
知识路由三级漏斗:用户提问后,系统不是直接全库检索,而是先走一轮 Scope → Topic → Document 的三级排序漏斗,通过语义 + 词法 + 关键词实体的混合打分,自动锁定最相关的文档,再进入检索链路。路由置信度不够时会主动降级,不会硬猜
-
影子路由质量观测:当用户手动选择文档时,系统在后台静默跑一遍完整的知识路由,对比"系统会选什么"和"用户实际选了什么",把命中率、置信度、候选排名等数据全部记录下来,用于持续评估和优化路由模型,整个过程对用户完全无感
-
RAG 前置编排引擎:路由判定、问题改写、子问题拆分、知识域收缩、歧义澄清,在模型回答之前把所有决策做完,确保每一次检索都是精准的
-
双通道混合检索:向量检索 和 关键词检索 并行执行,RRF 融合排序,可选外部 Rerank 精排,召回率和精准度兼顾
-
证据预算控制与无证据短路:模型上下文窗口有限,多子问题的证据量需要严格裁剪;没有找到相关证据时直接告知用户,不让模型凭空编造,从架构层面杜绝幻觉
-
Parent-Child 块聚合:检索粒度用 Child 小块保证命中率,回答阶段通过聚合提升到 Parent 大块,保证上下文完整性。这个设计在业界也属于比较前沿的实践
-
三种会话记忆策略:无记忆、滑动窗口、摘要压缩,生产环境下怎么平衡 Token 成本和上下文完整性,三种方案都有完整实现和对比演示
-
MCP 工具协议集成:基于 Model Context Protocol 标准协议,Agent 可以动态发现和调用外部工具,不再局限于硬编码的 Function Call,真正实现了工具能力的即插即用
-
Skills 能力扩展体系:通过 SKILL.md 配置文件声明式定义技能,支持目录结构化管理、自动加载、引用脚本和参考资料,让 Agent 的能力边界可以持续扩展而不需要改动核心代码
-
文档从上传到可检索的完整链路:Tika 多格式解析、四种切块策略组合流水线、向量化、向量数据库 + 倒排数据库 双引擎索引,每一步都有独立的任务日志和状态追踪
-
组合式切块引擎:—结构切块做主干、递归分块做兜底、语义分块做边界优化、LLM 智能切块处理疑难文档,系统按文档类型自动推荐最优策略组合
-
联网搜索与工具调用:集成 Tavily 搜索,支持工具重试、指数退避、异常兜底,模型调用次数和工具调用次数都有 Hook 限制,防止资源滥用和死循环
-
推荐追问问题生成:主回答完成后额外调用模型,生成最多 3 个可继续追问的问题,引导用户深入探索
-
SSE 流式输出协议:正文分片实时推送,结束时补发引用来源和推荐问题,支持主动停止生成,用户体验对标主流 AI 产品
用户在输入框里敲了一句话,点了发送。看起来很简单,但在 Super Agent 内部,这条消息要经过一条远比你想象中复杂的链路,才能变成一个靠谱的回答。
先看整体流程,后面再逐块拆解每个环节的设计细节:

核心思路是:不是让 Agent 自己决定所有事情,而是先用确定性的编排逻辑做好决策,再把执行交给最合适的引擎。 知识问答走稳定的证据驱动生成,开放式问题才走 Agent 自由探索。
面试中聊 Agent,面试官不想听你说"我用了 ReactAgent",他想听的是你对这些问题的思考:
-
用户提了一个问题,系统是怎么决定用哪种方式来回答的? 不是让模型自己选,而是先经过路由判定、问题改写、歧义检测这一整轮编排,最后才决定走哪个执行器。判断顺序是:歧义澄清 > 知识问答 > 开放式 Agent
-
为什么不是所有问题都走 Agent? 知识问答追求"稳"和"可解释",让 Agent 自己探索反而容易不可控。只有真正需要联网搜索、多步推理的开放式问题,才适合走 Agent
-
Agent 死循环了怎么办? 用 ModelCallLimitHook 限制单次运行最多调用模型 8 次,用 ToolCallLimitHook 限制 Tavily 搜索最多调 6 次。单个会话线程累计也有上限,分别是 40 次和 30 次
-
联网搜索调用失败了怎么处理? ToolRetryInterceptor 做指数退避重试,最多重试 2 次,初始延迟 200ms,最大延迟 1200ms,带随机抖动。如果最终还是失败,ToolErrorInterceptor 做兜底,不让异常直接抛给用户
-
对话状态怎么持久化? 用 Spring AI Alibaba 的 MysqlSaver 把 ReactAgent 的 Checkpoint 存到 MySQL,应用重启后能继续之前的对话
-
并行工具执行怎么做? ReactAgent 配置了 parallelToolExecution,最多 4 个工具并行执行
这些设计在代码里都能找到对应实现,不是概念上的东西。

知识问答追求"稳"和"可解释"——用户问"退款规则是什么",你需要的是从文档中精准检索证据,然后让模型基于证据生成回答。这种场景让 Agent 自己探索反而容易不可控,可能跑去联网搜索一堆无关内容。
而"今天北京天气怎么样"这种问题,知识库里根本没有答案,必须让 Agent 调用搜索工具去获取实时信息。
所以 Super Agent 设计了三层执行器,按场景精准分流:
| 执行器 | 触发条件 | 处理方式 |
|---|---|---|
| 歧义追问执行器 | 用户问题信息量不足,无法确定意图 | 生成澄清问题,引导用户补充信息 |
| RAG 知识问答执行器 | 问题可以在知识库中找到答案 | 证据驱动生成,引用来源可追溯 |
| ReAct Agent 执行器 | 需要联网搜索、多步推理的开放式问题 | 自主决策 + 工具调用 + 多轮推理循环 |
判断顺序是:歧义澄清 > 知识问答 > 开放式 Agent。优先用最稳定的方式回答,只有确实需要自由探索时才启动 Agent。
前面说了系统不会把所有问题直接扔给模型,而是先做一轮完整的编排。它在每次对话中做的事情远比你想象的多:
用户发进来的消息,首先要判断它属于哪种类型。是一个可以在知识库里找到答案的问题?还是需要联网搜索的开放式问题?还是信息不全需要先追问?这个判定不是靠关键词匹配,而是通过模型分析上下文后给出路由方向。
用户的问题往往不适合直接检索。比如"那它怎么配置?"——"它"指的是什么?得结合前几轮对话才知道。问题改写就是把这些省略的信息补回来,让检索能找到东西。
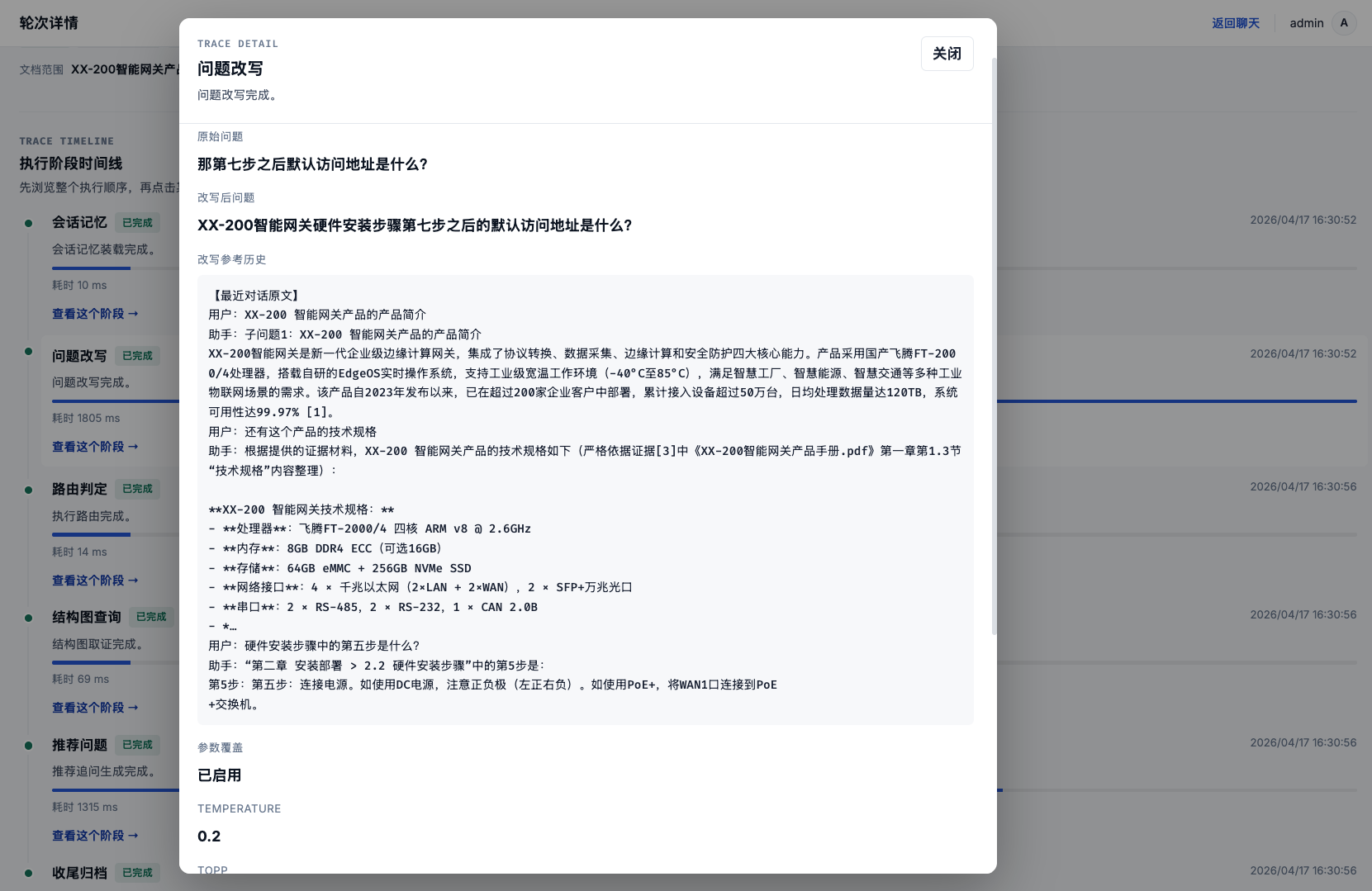
"退款规则是什么?审批流程怎么走?"这种复合问题,如果直接拿去检索,两个意图互相干扰,效果很差。系统会拆成独立子问题,每个单独走检索链路,最后合并结果。单轮最多拆 4 个子问题,避免过度切碎。
拆完子问题后,还要分析每个子问题属于哪个知识域,把检索范围从"全库"缩小到"相关领域"。这一步直接影响检索的精准度和速度。
如果用户的问题信息量不够,比如只说"查一下那个",系统不会硬着头皮去检索,而是先生成澄清问题让用户补充信息。这比返回一个不相关的答案体验好得多。
所有这些步骤完成后,编排器会产出一个 执行计划,里面包含执行多种执行编排模式、改写后的问题、拆分后的子问题列表、知识域范围等,交给对应的执行器去执行。

很多人以为检索过程就是"查个向量库 + 让模型回答",但实际上中间的环节比想象中多得多。下面列的这些问题,在项目中都有对应的设计:
- 用户问"那它怎么配置?"这种省略了主语的追问,直接拿去检索什么都找不到。所以要先做问题改写,结合最近几轮历史把指代补全
- 一个问题里问了两件事,比如"退款规则是什么?审批流程怎么走?",不能一股脑去检索。要拆成独立子问题,每个子问题单独走检索链路
- 单轮最多拆 4 个子问题,避免过度切碎
- 不是只用向量检索。用户问一个订单号、一个配置项名,向量检索很可能找不到。所以用了双通道并行:向量检索走 + 关键词检索
- 两路结果分数量纲完全不同,不能直接比大小。用 RRF(Reciprocal Rank Fusion) 按排名倒数法融合
- 向量通道设了最低相似度,关键词通道用相对阈值,低于阈值的弱命中直接过滤掉
- 融合后可以接外部 Rerank 精排(支持 SiliconFlow 兼容协议),在较干净的候选集上继续优化排序
- 检索粒度用 Child 小块保证命中率,回答阶段通过 Parent-Child 聚合提升到 Parent 大块,保证上下文完整性
- 如果最终没有任何有效证据,直接短路返回,告诉用户"当前文档中没有检索到足够证据"。不让模型凭空编造,这是防止幻觉最直接的手段
- 如果证据太多,有预算控制:单个子问题字符、全部证据总预算,单个父块最大字符。防止把模型上下文窗口吃满
- 按子问题边界分别组织证据,注入到 Prompt 里,模型按编号逐一回答
- 要求模型在引用证据时标注来源编号
[1][2] - 答案通过 SSE 实时流式推送,结束时补发引用来源和推荐追问问题

用户问一个订单号、一个配置项名,向量检索很可能找不到——语义相似度对精确匹配天然弱势。所以 Super Agent 用了双通道并行:向量检索 + 关键词检索,两路同时出发,互不阻塞。
两路结果的分数量纲完全不同,不能直接比大小。系统用 RRF(Reciprocal Rank Fusion) 按排名倒数法融合,向量通道设了最低相似度阈值,关键词通道用相对阈值,低于阈值的弱命中直接过滤。融合后还可以接外部 Rerank 精排,在较干净的候选集上继续优化排序。
这是整个检索链路中最精巧的设计之一。检索粒度用 Child 小块保证命中率——小块语义集中,更容易被向量检索命中。但回答阶段如果只用小块,上下文往往不完整。所以系统在命中 Child 块后,自动聚合提升到 Parent 大块,保证回答时有足够的上下文信息。
检索用小块保精度,回答用大块保完整性。 这个设计在业界也属于比较前沿的实践。
很多项目的文档处理就是"切成固定长度 → 向量化 → 完事"。但实际上不同文档差异很大,一刀切的效果很难好。Super Agent 的文档处理是一条完整的异步流水线,每一步都有独立的状态追踪和任务日志:

文件上传到 MinIO 对象存储后,通过 Kafka 异步触发解析任务。Apache Tika 负责处理 PDF、Word、PPT 等多种格式,把五花八门的文档统一转成干净的文本。PDF 里的表格、扫描件、双栏排版——每一个都是坑,Tika 帮你踩过了。
并且可以配置 知识域编码、知识域名称、业务分类、文档标签 等元信息,后续检索和分析都能用得上。
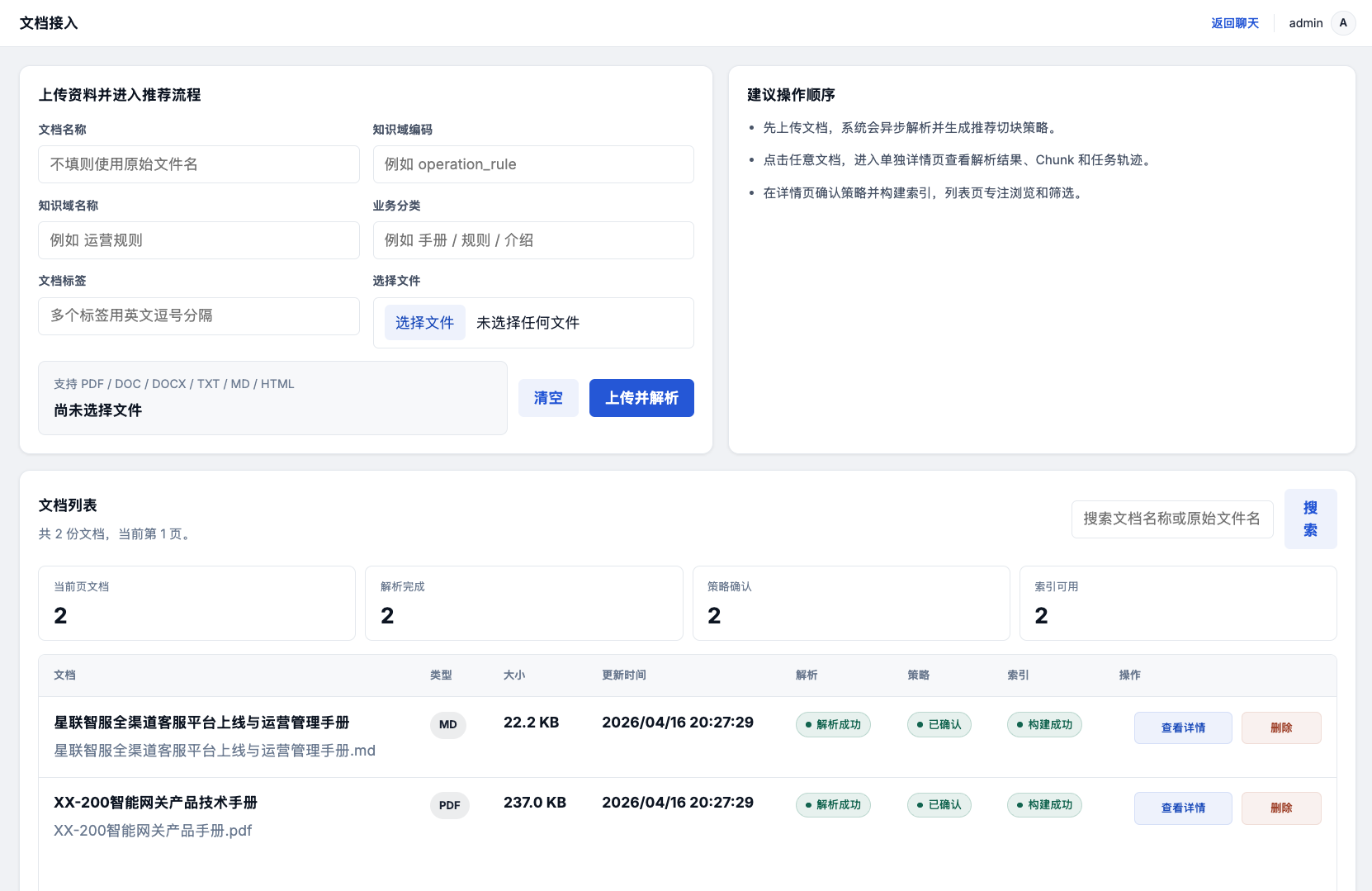
解析完成后,系统不是让用户盲选切块算法,而是根据文档类型和内容特征自动推荐最优的切块策略组合。用户可以查看推荐结果,也可以手动调整——比如文档质量不太好,可以额外开启 LLM 智能切块。
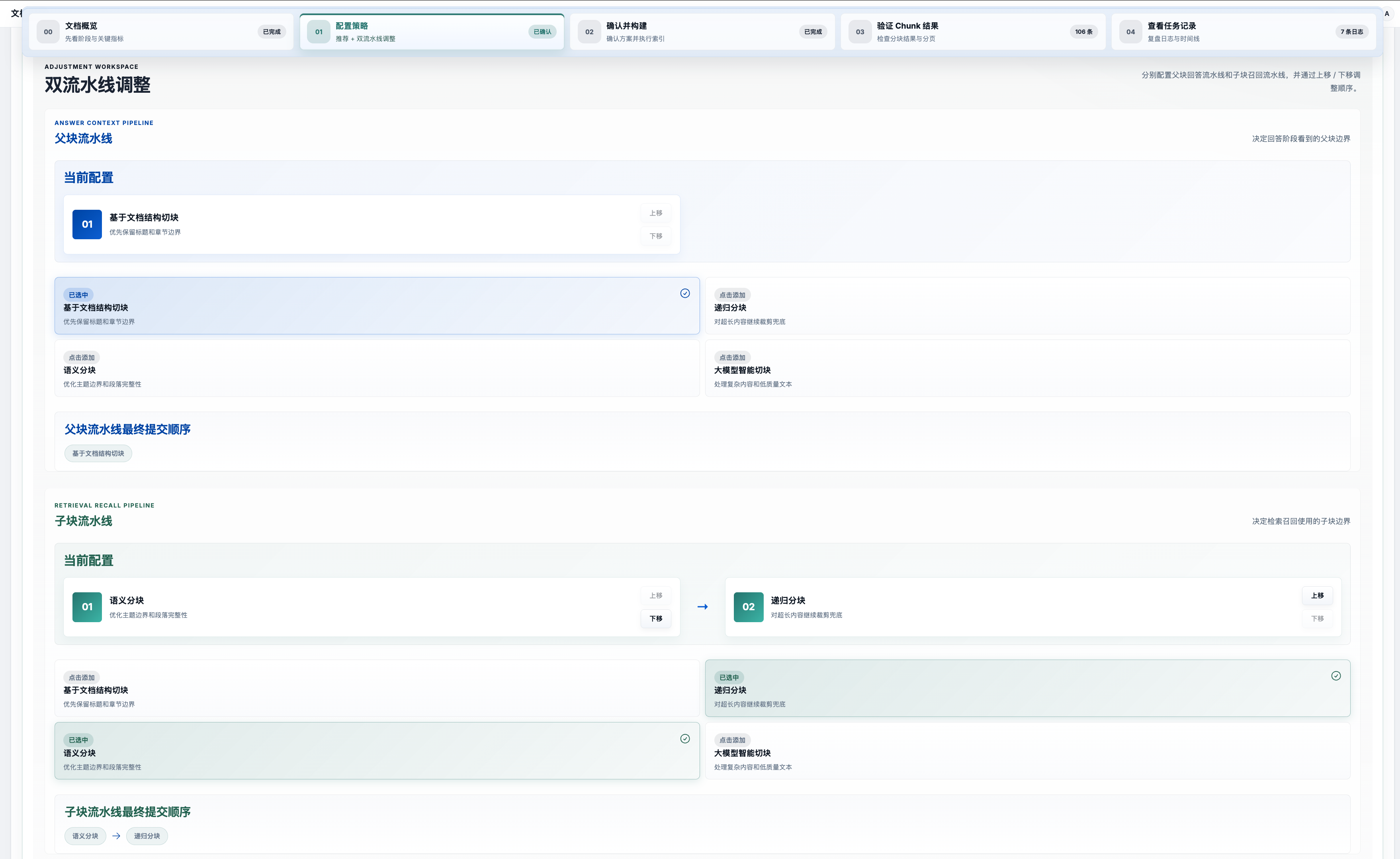
四种切块策略不是四选一,而是各司其职的组合流水线:
| 策略 | 角色 | 什么时候用 |
|---|---|---|
| 基于文档结构切块 | 主干 | 按标题/章节/段落切成语义完整的块 |
| 递归分块 | 兜底 | 结构块太大时继续往下裁剪,控制块大小 |
| 语义分块 | 优化 | 在结构切块基础上做边界精修 |
| LLM 智能切块 | 增强 | 处理低质量文档和复杂文档,默认关闭 |
一句话:结构负责保留文档天然边界,递归负责控制块大小,语义负责优化块边界,大模型负责处理疑难场景。
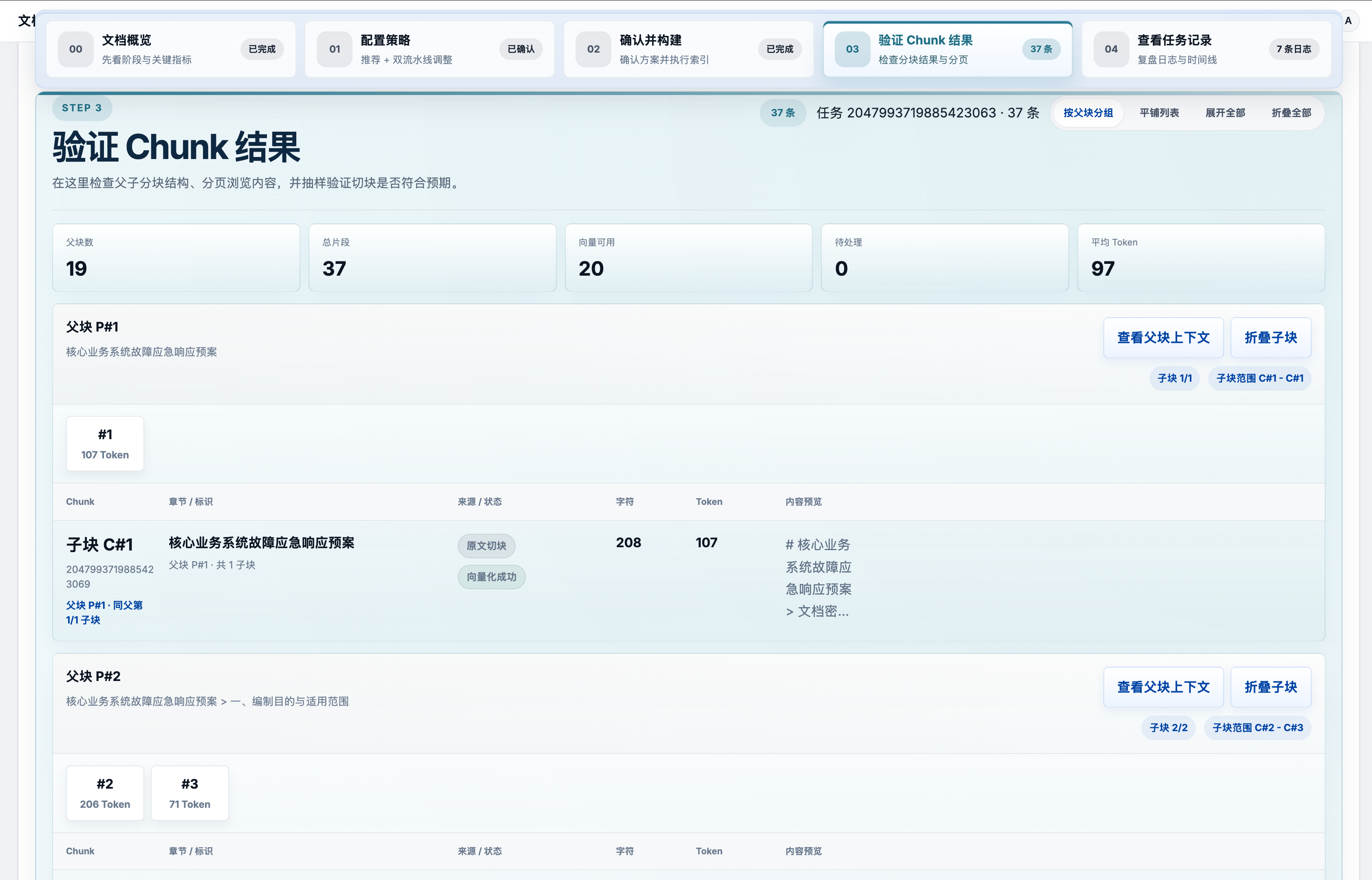
确认策略后,系统通过 Kafka 异步执行向量化和索引构建。向量写入向量数据库,关键词写入倒排索引数据库,构建双通道检索的基础。每一步都有独立的任务日志,出了问题能精确定位到哪一步失败。
20 轮对话全塞给模型?Token 成本扛不住。只带最近几轮?可能丢掉关键上下文。这是生产环境下绕不开的问题。

- 无记忆:每轮独立,不携带历史。适合一次性查询
- 滑动窗口:保留最近 N 轮完整对话。适合短期连续追问
- 摘要压缩:长期摘要 + 最近原文窗口。这是生产环境最推荐的方案
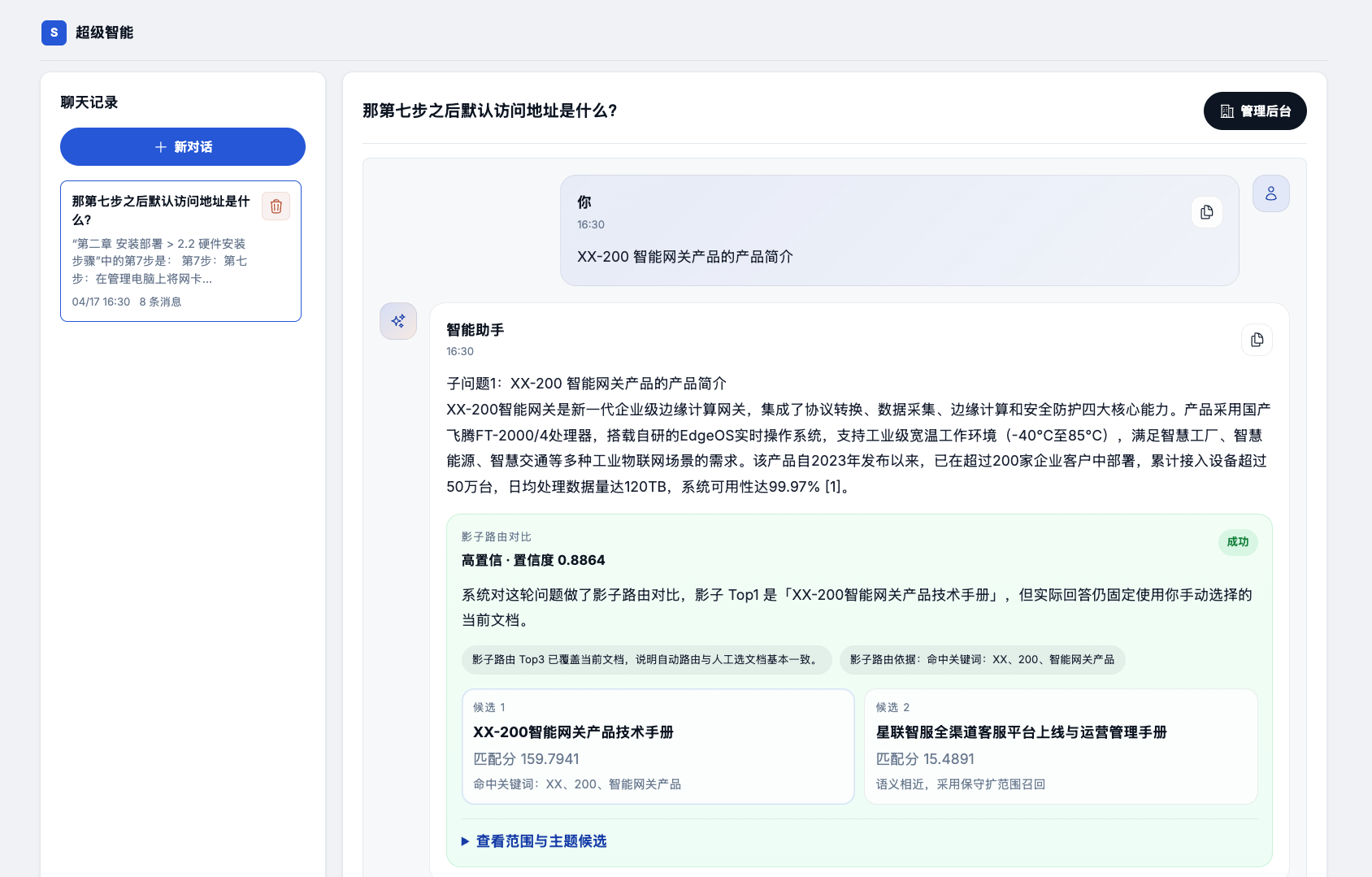
- 最近 4 轮原文始终保留,不做压缩
- 更早的历史增量摘要,单次最多推进 6 轮,避免一次处理超长历史
- 最近原文窗口最大 2200 字符,长期摘要最大 1400 字符
- 所有记忆数据持久化到 MySQL,应用重启不丢失
Agent 的价值不只是能聊天,更在于能调用外部工具完成实际任务。Super Agent 在工具集成这块做了两层设计:
MCP(Model Context Protocol)是 Anthropic 提出的开放协议标准,定义了模型与外部工具之间的通信规范。Super Agent 基于 MCP 协议实现了完整的工具调用链路:
- 动态工具发现:Agent 启动时自动扫描并注册可用的 MCP 工具,不需要硬编码工具列表
- 标准化通信:工具的输入输出遵循 MCP 协议规范,支持 Stdio 和 SSE 两种传输模式,兼容主流 MCP Server 生态
- 参数自动提取:模型根据用户意图自动识别需要调用的工具并提取参数,无需用户手动指定
- 多工具编排:单次对话中可以串联调用多个 MCP 工具,前一个工具的输出可以作为后一个工具的输入
- 安全沙箱:工具调用在受控环境中执行,有超时限制和异常隔离,防止恶意工具影响主流程
相比传统的 Function Call 硬编码方式,MCP 协议的优势在于标准化和可扩展性——新增一个工具不需要改任何业务代码,只需要部署一个符合 MCP 协议的 Server 即可。
Skills 是比 MCP 更上层的能力抽象,解决的是"Agent 怎么获得特定领域的专业能力"这个问题:
- 声明式定义:每个 Skill 通过
SKILL.md配置文件描述能力边界、触发条件、执行逻辑,结构清晰易维护 - 目录化管理:Skills 按领域组织成目录结构,支持嵌套分类,方便大规模能力管理
- 自动加载机制:系统启动时自动扫描 Skills 目录,新增 Skill 只需要放入对应目录,零配置生效
- 引用脚本与参考资料:Skill 可以关联外部脚本(Python、Shell 等)和参考文档,执行时自动加载上下文
- 能力组合:多个 Skills 可以组合使用,Agent 根据任务需求自动选择最合适的 Skill 组合
Skills 体系让 Agent 的能力边界不再是固定的,而是可以持续扩展的。今天加一个"数据分析"Skill,明天加一个"代码审查"Skill,Agent 的能力就跟着增长,核心代码一行不用改。
说一个项目是企业级,得看实际的工程质量。从几个维度来评估 Super Agent:
- 分层架构:business / common / framework 三层职责清晰,AI 业务逻辑、通用 Web 能力、基础设施组件互不耦合
- 统一异常处理:全局异常拦截 + 统一响应格式 ApiResponse,业务代码不需要到处 try-catch
- 自动装配机制:基础组件通过 Spring Boot Starter 方式封装,引入依赖即可使用,零配置代码
- MyBatis-Plus 自动填充:创建时间、更新时间等公共字段自动处理,不需要每个 Mapper 手动设置
- API 文档规范:Knife4j 增强的 Swagger 文档,接口定义即文档
这是很多开源项目完全忽略的部分,但在生产环境中至关重要:
- Redis 租约互斥:
RedisLeaseManager实现集群级别的会话锁定,防止同一条消息被多个实例重复处理 - JVM 级任务注册:
ChatRuntimeRegistry维护进程内的任务注册表,防止同进程重入 - 租约续期:执行过程中自动续期,防止长对话超时导致锁释放后被其他实例抢占
- 优雅降级:无论成功还是失败,统一触发清理流程,不会留下孤儿锁
项目中落地了多种经典设计模式,不是为了用模式而用,每个都解决了实际的扩展性或解耦问题:
| 设计模式 | 应用场景 | 解决的问题 |
|---|---|---|
| 策略模式 | 三种会话记忆策略、四种切块策略 | 不同策略可插拔替换,新增策略不改已有代码 |
| 工厂模式 | 检索通道创建、切块器创建 | 复杂对象的创建逻辑集中管理 |
| 模板方法 | 文档处理流水线各节点 | 统一执行流程,子类只关注核心逻辑 |
| 责任链模式 | RAG 前置编排器的五步决策链 | 多个处理步骤按顺序串联,灵活组合 |
| 观察者模式 | SSE 流式输出回调 | 流式事件的异步通知与推送 |
| AOP | 重复执行限制、全局异常拦截 | 横切关注点与业务代码解耦 |
核心模块都预留了扩展点:
- 新增检索通道:实现检索通道接口,注册为 Spring Bean,自动参与双通道检索
- 新增切块策略:实现切块策略接口,可加入组合流水线的任意位置
- 新增记忆策略:实现记忆策略接口,系统自动识别并可配置使用
- 新增工具调用:给 ReactAgent 注册新的 Tool,自动参与工具选择
- 新增 MCP Server:部署符合 MCP 协议的 Server,Agent 自动发现并注册
- 新增 Skill:在 Skills 目录下放入 SKILL.md 配置文件,零配置即刻生效
不需要改框架代码,加个实现类或配置文件就完事了。这才是面向接口编程和插件化架构的正确打开方式。
基于 AOP 的全链路追踪,每个环节的耗时、输入输出、决策结果都有记录。思考过程、检索通道使用情况、证据来源、工具调用记录——全部可视化呈现在管理后台的观测面板中。出了问题不用猜,直接看 Trace 就知道哪一步出了问题。
市面上大多数 Agent 项目,说白了就是跑通一个示例就完事了。Super Agent 和这些项目的差距在哪?直接对比一下:
| 对比维度 | 普通 RAG 项目 | Super Agent |
|---|---|---|
| 检索方式 | 单路向量检索 | 双通道并行(PGVector + ES)+ RRF 融合 + 可选 Rerank |
| 问题处理 | 原始问题直接检索 | 改写 + 子问题拆分 + 知识域收缩 |
| 意图判断 | 无 | 前置编排器五步决策 + 歧义主动追问 |
| 执行策略 | 所有问题走同一个模型 | 三层执行器按场景分流(追问 / 知识问答 / Agent) |
| 会话记忆 | 全量塞给模型或不带 | 无记忆 / 滑动窗口 / 摘要压缩三种策略 |
| 文档切块 | 固定长度一刀切 | 四种策略组合流水线 + 系统自动推荐 |
| 文档入库 | 同步处理,无日志 | Kafka 异步流水线 + 分步骤任务日志 |
| Agent 能力 | 无或仅简单对话 | ReAct 循环 + 联网搜索 + 工具调用 + Checkpoint 持久化 |
| 证据控制 | 无 | 预算裁剪 + 无证据短路防幻觉 |
| 检索粒度 | 命中什么用什么 | Parent-Child 块聚合,检索用小块、回答用大块 |
| 流式输出 | 简单 SSE 推文本 | 正文 + 引用来源 + 推荐追问 + 停止生成 |
| Agent 安全 | 无限制 | 模型调用次数 Hook + 工具调用次数 Hook + 重试兜底 |
| MCP 协议 | 无或硬编码 Function Call | MCP 标准协议 + 动态发现 + 多工具编排 + 安全沙箱 |
| 能力扩展 | 固定能力,改代码才能加 | Skills 声明式定义 + 自动加载 + 热插拔扩展 |
| 集群安全 | 单机运行 | Redis 租约互斥 + JVM 任务注册 + 租约续期 |
| 可观测性 | 无 | 全链路 Trace + 可视化观测面板 |
| 知识路由 | 无,全库检索 | 三级漏斗(Scope → Topic → Document)+ 混合打分自动锁定文档 |
| 文档结构 | 无 | Neo4j 图数据库构建 Document → Section → Item 层级图谱 |
| 路由质量观测 | 无 | 影子路由静默对比 + 命中率追踪 + 持续优化闭环 |
一句话:每个环节都不是调个 API 就完事的,而是有完整的设计和工程考量。
- 简历上已经有了商城、外卖等常规项目,需要一个有区分度的项目来拉开差距。Super Agent 能让你在面试中聊 AI + 工程化,而不是千篇一律的 CRUD
- 想转 AI 应用方向但不想从 Python 入手。项目基于 Java 技术栈,学习曲线平滑
- 大厂校招越来越看重候选人对新技术的敏感度,简历上有 AI 项目经验,能直接证明学习能力和技术视野
- 1-3 年经验:日常写业务代码,想往 AI 方向转型但不知道从哪下手。技术栈你都熟悉,学的是 AI 应用层的东西,上手快
- 3-5 年经验:技术能力不差,但面试被问到 AI 相关问题答不上来,少了一个谈薪筹码。通过项目补上 RAG、Agent 这些知识点,面试时能聊得有深度
- 想跳槽到 AI 团队:越来越多的 JD 要求有 AI 相关经验,项目能帮你快速建立 RAG 系统的全局认知
一句话:学完 Super Agent,你既能跟面试官聊 RAG、Agent、MCP 的技术深度,也能证明自己的项目工程化水平。不管是校招还是社招,这个项目都能成为你简历上最有区分度的一笔。
为了更好地帮助大家学习 Super Agent 项目,配置了非常详细完整的文档和视频,把每个知识点都会讲到,包括非常全的 AI 的技术知识,以及项目中如何使用的、为什么这么用、形成从 AI 基础到项目实战的一套完整体系。学习过程中遇到问题可以在社区反馈,本人会详细解答。
小伙伴想要实时关心项目更新的进展情况的话,可以关注公众号:阿星不是程序员
在项目中的学习过程中遇到了什么问题或者有哪些建议,欢迎添加本人wx,备注:super 来领取详细的项目学习资料
